.png?width=250&height=56&name=stonewater-logo%20(1).png)



Machine Learning - deployment anytime, anywhere
Utilise your on-prem and cloud footprint with Microsoft Azure Machine Learning and Azure Arc
Contents
- Introduction
- Set up Azure Arc ML
- Real world examples
- Case study: Wolters Kluwer Health
- Enterprise-grade ML for all sized organisations
- Appendix A: Azure-arc enabled ML architecture
- Appendix B: Built-in Azure Machine Learning capabilities and Azure-enabled ML
- Appendix C: Azure Arc and Machine Learning
Introduction
Machine learning (ML) has many applications for organisations of all sizes - and the possibilities are constantly expanding. It can help uncover insights into business data, enhance the user experience for customers, and reduce business risk. And while ML can pose unique challenges for organisations, technologies from Microsoft can help you overcome those challenges and harness the benefits of ML.
Azure Machine Learning can help your data team rapidly build and train models and operationalise them at scale with MLOps. It also lets your data team innovate on an open and flexible platform, all while building reliable ML solutions that protect data and models.
Azure Arc is a set of technologies that extends Azure management and services to any infrastructure. It enables you to build and deploy cloud-native apps and ML models anywhere, at scale. It also provides central visibility, operations, and compliance, allowing organisations like yours to run Azure services like Azure Machine Learning anywhere.
Azure Machine Learning integrates with Azure Arc to give you Azure Arc-enabled ML. With Azure Arc-enabled ML capabilities, organisations like yours can use Azure Machine Learning anywhere across one or more clouds, on-premises, or the edge.
PII and data sovereignty: Drug discovery
Multi-cloud: Medical imaging
Regulatory compliance: Consumer banking
ML on the edge: Renewable energy
Microsoft case study: Wolters Kluwer Health
The assurances and the challenges of ML
ML can bring unprecedented benefits to organisations that embrace it. It can help identify patterns or structures within both your structured and unstructured data, helping you to identify new opportunities. It can deepen your data mining capabilities to find new relationships - and to improve its abilities over time. It can also help reduce business risk by identifying new patterns and tactics to head off fraud.
The challenges to realising all of the benefits of ML are two-fold: the operations that run ML and the data that powers it. ML operations can pose challenges to enterprise IT organisations because traditional IT management tools are not well-suited for managing ML. At the same time, the data that fuels ML brings unique challenges in terms of quantity and potential sensitivity that can require entirely new processes to meet them. Azure Arc-enabled ML integrates services and technologies from Microsoft that can supply your organisation with the specialised capabilities necessary to realise the benefits of ML.
The unique tools within ML
ML models have unique characteristics that require specific tools, technologies, and practices to operationalise at scale. Not only must organisations manage the creation of software - the ML models - but the data used to create those models must also be engineered as well. These pipelines must link up with workflows already in place for solution development.
Once trained and tested, ML models must also be put into production so that they have access to all their dependencies. Once deployed, the performance of ML models is expected to drift over time as the data used on those models changes. Organisations must continuously monitor their ML models while in production and retrain, repackage, and redeploy them as necessary. Moreover, oftentimes these operations will need to be carried out close to the data for reasons of compliance, latency, or data gravity. For all of these reasons, traditional software deployment practices such as DevOps are insufficient to operationalise ML at scale.
Operationalising a single ML model can be challenging; deploying multiple models in production at an enterprise scale can be daunting. ML models have multiple software dependencies, and they often need specialised infrastructure for optimal performance. And as models drift or other business metrics for model performance change, ML models must periodically be retrained on new data.
Set up Azure Arc ML
Azure Arc-enabled ML combines the capabilities of Azure Arc and Azure Machine Learning. Azure Arc brings Azure management and services to any infrastructure, providing you with a single pane of glass to manage your entire Kubernetes infrastructure on-premises and across clouds. Azure Machine Learning is an enterprise-grade service that enables your data scientists and developers to innovate rapidly using familiar tools and your organisation to operationalise ML at scale with MLOps. Azure Machine Learning integrates with Azure Arc to give you Azure Arc-enabled ML. Azure Arc-enabled ML capabilities enable your organisation to run enterprise-grade ML workloads on Kubernetes anywhere with the same easy-to-use Azure Machine Learning experience found in the cloud with centralised visibility, operations, and compliance.
Capabilities
Azure Arc-enabled ML enables Azure Machine Learning to provide management for MLOps, rapid innovation for ML, and efficient ML operations on-premises, in the cloud, and at the edge.
Unified management
Azure Arc provides single-pane management through the Azure portal. All ML models, no matter where they’re built, can be stored and tracked in a central location in Azure Machine Learning for sharing, reproducibility, and audit compliance.
ML is predicated on reproducibility and reusability. This extends from ML models to the whole ML lifecycle. Regardless of its application, ML follows a consistent lifecycle, which is supported at each stage by Azure Machine Learning:
-
Build - Data scientists create their initial models and then clean and prepare datasets to be usable by those models.
-
Train - With the data prepared, data scientists use it to train models.
-
Validate - Once the models are trained, ML engineers create containers for their models to run in with all their dependencies, and the data team evaluates how model performance compares to their business goals.
-
Deploy - The data team deploys the models to scale out inference clusters in the cloud or on-premises to be used on new data.
-
Monitor - As the models are used in production, the data team monitors them for degraded performance and retrains them as necessary to keep them relevant to business operations.
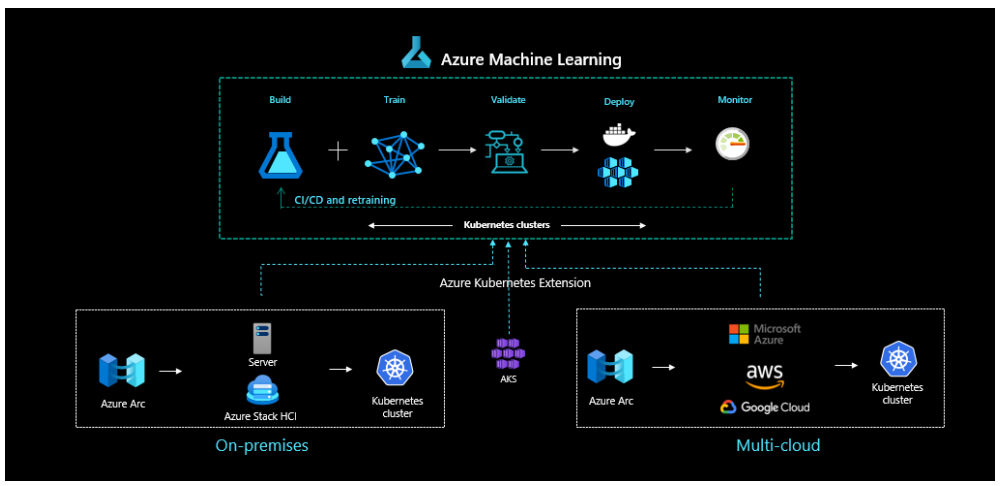
Figure 1. The entire ML lifecycle is managed at all levels by Azure Arc-enabled ML
With whole-of-lifecycle management and tracking, data science can become tenable for organisations of all sizes. With an efficient means of versioning and monitoring the entire ML lifecycle, organisations can head off irreproducible experiments and training runs. This can decrease the time for the whole ML lifecycle and the chance of errors. Moreover, with automated MLOps, Azure Arc-enabled ML enables organisations to unlock the power of infrastructure based on Kubernetes to run enterprise-grade MLOps.
Rapid innovation
Azure Machine Learning supports open-source tools and frameworks for ML model training and inferencing out of the box. Your data scientists can use familiar frameworks like PyTorch, TensorFlow, or scikit-learn, and they can choose the development tools that best meet their needs, including popular integrated development environments (IDEs), Microsoft Visual Studio Code, Jupyter Notebooks, and command-line interfaces (CLIs), or programming languages like Python and R.
With Azure Machine Learning, your organisation can access state-of-the-art responsible ML capabilities to understand, control, and help protect your data, models, and processes. This insight can help you explain model behaviour during training and inferencing and build for fairness by detecting and mitigating model bias. Transparency such as this can help your organisation meet regulatory compliance with its ML operations, as can the capability of Azure Machine Learning to preserve data privacy throughout the ML lifecycle with differential privacy techniques and using confidential computing to help secure ML assets. And Azure Machine Learning automatically maintains audit trails, tracks lineage, and uses model datasheets to enable accountability.
Azure Machine Learning also enables you to auto-scale compute resources for ML. Typical ML-model development starts with development or experimentation on a small amount of data, at which stage a single on-premises instance or a cloud-based virtual machine (VM) is sufficient. However, as you scale up your model training on larger datasets or perform distributed training, Azure Machine Learning creates clusters that auto-scale with each training run to provide sufficient compute resources.
IT and ML personas and experiences
The IT operations and data-science teams are integral to the broader ML team. Azure Arc-enabled ML enables the ML team to use of the advantages of Kubernetes - such as containerisation and separation of roles - without the ML infrastructure team or data-science professionals needing to learn Kubernetes. Separating roles makes collaboration more straightforward, as it can be based on different skill sets.
IT operators
IT operators are responsible for setting up the computing resources to be used by the data science team. To get a Kubernetes cluster up and running for Azure Arc-enabled ML for data-science professionals, IT operators need to complete the following tasks (see Figure 3):
-
Ensure that the Kubernetes cluster is up and running.
-
Connect to Azure with Azure Arc.
-
Deploy the Azure Machine Learning extension to the Kubernetes cluster to support the necessary scenario:
a. Enable the cluster for model training only.
b. Enable the cluster for model deployment only (administrators can set up an endpoint with a public/private IP address and Transport Layer Security [TLS] termination proxy).
c. Enable the cluster for both training and model deployment. -
Create compute targets in Azure Machine Learning workspaces to which data-science professionals submit workloads, and attach the Kubernetes cluster to the Azure Machine Learning workspace.
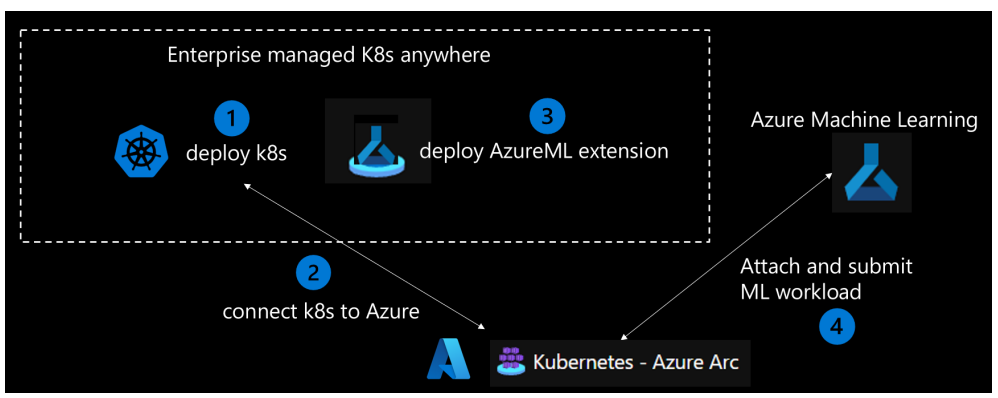
Figure 2. Tasks to deploy and start a Kubernetes cluster for Azure Arc-enabled ML
Administrators can control which engineers and data scientists have access - and they can grant access to entire clusters or selected parts of clusters. ML models and their dependencies can be packaged in discrete Kubernetes containers for deployment without data scientists needing to know Kubernetes.
Data-science professionals
With Azure Arc-enabled ML, data-science professionals can submit ML workloads using compute targets created by IT operators:
-
Data scientists can select the tools they like to use. Azure Arc-enabled ML provides different tools, such as a CLI, the Azure Machine Learning Studio user interface (UI), or the Python SDK (programmatic). The data scientists can then direct those tools to use the compute targets set up by IT operators.
-
Technical note: To make this process even easier for data scientists and practitioners, they can use Git to clone examples from the Azure Machine Learning repository and then change the compute targets in the examples to their desired compute targets to quickly get up and running: github.com/Azure/azureml-examples.
-
Data scientists determine which features are supported in Azure Arc-enabled ML to use. (For a list comparing the Azure Machine Learning built-in features and features supported in Azure Arc-enabled ML, see Appendix B.)
Typical Azure Arc-enabled ML use patterns
Table 1 summarises the typical use patterns for Azure Arc-enabled ML, including where the training data resides in each use pattern, the motivation driving each use pattern, and how the use pattern is realised using Azure Arc-enabled ML.
Table 1. Summary of the typical use patterns for Azure Arc-enabled ML
| Use pattern | Location of data | Motivation | Implementation in Azure Arc-enabled ML |
|---|---|---|---|
|
Train models in the cloud, deploy models on premises
|
In the cloud
|
Make use of cloud computing, either because of elastic computing needs or special hardware in the cloud, such as a graphics processing unit (GPU)
Model must be deployed on-premises because of security, compliance, or latency requirements |
Fully automated MLOps, including training and model deployment steps transitioning seamlessly from cloud to on-premises deployment
Repeatable, with all assets tracked properly Model to be retrained when necessary, with on-premises model deployments updated automatically when retrained |
|
Train models on-premises, deploy models in the cloud
|
On-premises
|
Data must remain on-premises due to data-residency requirements
Deploy model in the cloud for global services access or for compute elasticity for scale and throughout |
Read the above
|
|
ML with network isolation (in cloud or on-premises
|
In the cloud or on-premises
|
Secure sensitive data or proprietary IP, such as ML models
|
In the cloud:Azure Kubernetes Service (AKS) private cluster with a private link to Azure Machine Learning workspaces; models deployed with private IP address
On-premises: Outbound proxy connection server and Azure ExpressRoute/virtual private cloud connection and private links to Azure Machine Learning workspaces; models deployed with private IP adresses |
Note that with the network-isolation use pattern, multiple workspaces share the same Kubernetes cluster. Each business or project team has its own workspace but uses the same Kubernetes cluster to save compute costs and minimise IT management and maintenance overhead.
Challenge
Banks frequently need to run financial risk-modelling predictions for things like consumer and small-business loans, and they rely heavily on ML models to make lending decisions. While banks’ risk models might be trained in data centres or the cloud, they often need to run ML on-premises to meet their regulatory requirements. Banks must also be able to transparently show regulators and other stakeholders how lending decisions were made through the ML models.
Solution
The hybrid-cloud capabilities of Azure Machine Learning help address these needs. For example, bank risk models can be trained in one or multiple clouds or at a bank data centre and then deployed on-premises to a bank branch. Moreover, the bank can use centralized MLOps to manage the lifecycle of its risk models regardless of where they are trained and deployed. Not only can this help a bank meet its regulatory requirements regarding customer data, but it can also enable the deployment of ML models even to bank branches with limited internet connectivity. (For a breakdown of some of the details of using Azure Arc-enabled ML this way, see the Train models in the cloud, deploy models on-premises and Train and deploy models on-premises use patterns in Table 1.)
Challenge
Pharmaceutical companies must both protect sensitive patient data in drug trials and also conform to data sovereignty issues as to where trial data can be analysed. Beyond patient data, drug-discovery firms also want to secure proprietary data concerning candidate drugs and delivery procedures. There can be numerous circumstances in which pharmaceutical companies must isolate their data, models, and networks. At the same time, data scientists with these firms need to be able to use the same tools for data exploration and model building, regardless of where datasets reside.
Solution
Because Azure Arc-enabled ML enables models - including existing models trained outside of Azure Arc-enabled ML - to be deployed to almost any environment (be it on-premises, on the network edge, or in one or multiple clouds), pharmaceutical firms can train, tune, and deploy their models anywhere, even in isolated, locked-down networks. Doing so can help secure patients' personally identifiable information (PII) and corporate IP during drug research, discovery, and trials. What is more, administrators can still provide comprehensive MLOps to these isolated deployments to maintain efficiency along with security. (For a breakdown of some of the details of using Azure Arc-enabled ML this way, see the ML in network isolation (in the cloud or on-premises) and Train and deploy models on-premises use patterns in Table 1.)
Challenge
Healthcare organisations commonly need multi-cloud support, given their inter-organisational collaboration structures. Patient data can be scattered between private practices, hospitals, and even different hospital systems - and consolidation within the healthcare industry can result in multiple legacy cloud infrastructures within a single organization. At the same time, healthcare organisations need to secure patient PII and share only the necessary details for patient care.
Solution
Using Azure Arc-enabled ML, healthcare organisations can efficiently perform multi-cloud ML. Models can be trained where patient data is, which can be vastly more efficient in cases using large data files, such as medical imaging. Models can then be deployed to other locations. Organisations can infer medical-images ML models using spare compute on-premises or at edge locations and burst to cloud capacity as the need arises. Moreover, ML administrators can still track all these models to automate the process of deploying retrained models in the future through centralized and automated MLOps. (For a breakdown of some of the details of using Azure Arc-enabled ML this way, see the Train models in the cloud, deploy models on-premises and Train and deploy models in one or more clouds use patterns in Table 1.)
Challenge
Wind farms are a great renewable energy source, but their power output fluctuates greatly depending on wind speed and other environmental factors. Wind farms generate petabytes worth of data continuously on site, and that can be unfeasible to move to the cloud. In addition, ML models can help forecast energy capacity, make power commitments, and facilitate predictive maintenance, but wind farms can have limited or intermittent internet connectivity.
Solution
With Azure Arc–enabled ML, models can be trained on premises without data movement. Wind energy firms don’t have to worry about the economics of shipping data. Models trained at a data centre or in one or multiple clouds can be deployed to the wind farm and used even without internet connectivity. And automation and MLOps with Azure Arc–enabled ML help to ensure that as data at the wind farm changes, the models retrain themselves and maintain accuracy. (For a breakdown of some of the details of using Azure Arc–enabled ML this way, see the Train models in the cloud, deploy models on-premises and Train and deploy models on-premises use patterns in Table 1.)
Case Study: Wolters Kluwer Health
The Health Division of Wolters Kluwer provides trusted clinical technology and evidence-based solutions that engage clinicians, patients, researchers, students, and the next generation of healthcare providers. The Wolters Kluwer Health data-science team always strives to adopt technological advancements in building ML models rapidly and efficiently to serve multiple business units within Wolters Kluwer Health. Wolters Kluwer Health enacted modern management for its ML pipeline by re-architecting its ML practice using the primary components of Azure Arc-enabled ML: Azure Machine Learning, Azure Kubernetes Service, and Azure Arc.
Challenge
Isolated training workspaces
The Wolters Kluwer Health data science team previously used standalone Azure VMs to handle training datasets and ML models. Because manually managing and changing VM tiers based on the varied compute and memory demands of different training runs was cumbersome and impractical, the Wolters Kluwer Health development pipeline used standardised high-compute, large-memory tier VMs, which was costly. In addition, because training jobs were often left to run overnight and there was no practical way to track job completion and automatically shut down idle VMs, Wolters Kluwer Health was forced to pay for unused VM capacity consistently.
Beyond VM expenses, Wolters Kluwer Health had no efficient means of versioning and monitoring its whole model training process and its input/output (I/O) artefacts, which resulted in irreproducible experiments and training runs. The lack of versioned datasets, environments, and models increased development time and multiplied the chance of errors in models. Additionally, whenever the data-science team received updated datasets to retrain models, the entire ML lifecycle had to be rerun manually. This significantly slowed model evaluation and tuning. The Wolters Kluwer Health ML practice was not scalable.
Solution
Azure Machine Learning on Kubernetes
Wolters Kluwer Health got a handle on its ML pipeline by shifting to Azure Machine Learning. The data science team can now run quick experiments and ad-hoc tasks from within an Azure Machine Learning workspace, eliminating the inefficiencies of performing these tasks on standalone Azure VMs. Wolters Kluwer Health can use workflows in Azure Machine Learning to handle model training and tracking and automate model retraining. And now, rather than having to set up entire environments again to retrain ML models, Wolters Kluwer Health can simply plug in the new data to efficiently handle retraining models.
Wolters Kluwer standardised its infrastructure on Azure Kubernetes Service (AKS), and the data-science team can use a dynamically adaptable cluster model for its model training workflows. And because AKS instance deployment is handled by Wolters Kluwer IT, the data-science team was able to reduce its self-management overhead. Finally, Wolters Kluwer Health increased ML compute efficiency by using Azure Arc to enable inter-subscription sharing of AKS clusters across Azure Machine Learning workspaces.
Wolters Kluwer Health can now track ML assets, with full versioning of all dependent I/O artefacts, along with monitoring of and reproducibility for all training runs. AKS helps Wolters Kluwer Health share the centrally managed compute resources for multiple purposes across the organization, including its ML workflows. And Azure Arc helps Wolters Kluwer Health use the same Kubernetes cluster across multiple ML workspaces provisioned in multiple subscriptions. All of these benefits help the Wolters Kluwer Health data team achieve faster, better results for the many teams across Wolters Kluwer Health that they support.
Enterprise-grade ML for all-sized organisations
ML poses challenges both because of the unique characteristics of ML models and the surrounding data that powers it. For combinations of legal, logistical, and technical reasons, data cannot always be moved where it would be convenient for training or running ML models. And traditional development and administrative tools are ill-suited to managed ML models, particularly as they proliferate and move between clouds and on-premises locations. Even IT’s go-to DevOps solution, Kubernetes, has to be used in new and different ways for ML.
By combining the flexibility and efficiency of Azure Arc with the robust MLOps and operations capabilities of Azure Machine Learning, Azure Arc-enabled ML can help organisations overcome the unique challenges and complexities of ML. Azure Arc-enabled ML simplifies using Kubernetes in ML development and production environments. It also automates many aspects of the MLOps pipeline so that administrators do not have to spend their time wrestling with sprawling ML model deployments and all their dependencies or with rickety conglomerations of open-source tools. Azure Arc-enabled ML also brings the hybrid capabilities of Azure Arc to ML, meaning that models can be trained in one or more clouds or on-premises and then deployed either on-premises or to the cloud. This flexibility means that Azure Arc-enabled ML can simplify ML for almost every organisation in almost every set of circumstances.
To see Azure Arc-enabled ML in action and learn more about what it can do for your organisation, contact Microsoft to set up a proof of concept.
| Feature name | Features built into Azure Machine Learning | Features supported in Azure Arc-enabled ML |
|---|---|---|
|
Train with AzureML Python SDK v1.x
|
Yes
|
Yes
|
|
Train with AzureML CLI v2
|
Yes
|
Yes
|
|
Distributed training - MPI, tf.distributed, torch.distributed
|
Yes
|
Yes
|
|
Train with AzureML pipeline SDK v1.x
|
Yes
|
Yes
|
|
Train with designer pipeline
|
Yes
|
Yes
|
|
Deploy with SDK/CLI v1.x
|
Yes
|
No
|
|
Deploy with CLI v2
|
Yes
|
Yes
|
|
AKS and Azure Machine Learning workspace cross-subscription support
|
No
|
Yes (via Azure Arc)
|
|
Multiple workspaces share the same AKS cluster
|
No
|
Yes
|
|
Node pool targeting for workload
|
No
|
Yes
|
|
Training with NFA data access
|
No
|
Yes
|
|
Training with HDFS data access
|
No
|
In development
|
|
MLflow model integration
|
Yes
|
In development
|
|
MLOps (GitHub action)
|
Yes
|
Yes
|
|
Curated image support
|
Yes
|
Yes
|
|
Safe production rollout with green/blue deployment
|
Yes
|
Yes
|
|
ML with network isolation
|
Yes
|
Yes
|
|
Use managed identity to access Azure resources
|
Yes
|
Yes
|
|
Model-deployment bring-your-own-compute(BYOC) support
|
Yes
|
Yes
|
Appendix C: Azure Arc and Machine Learning
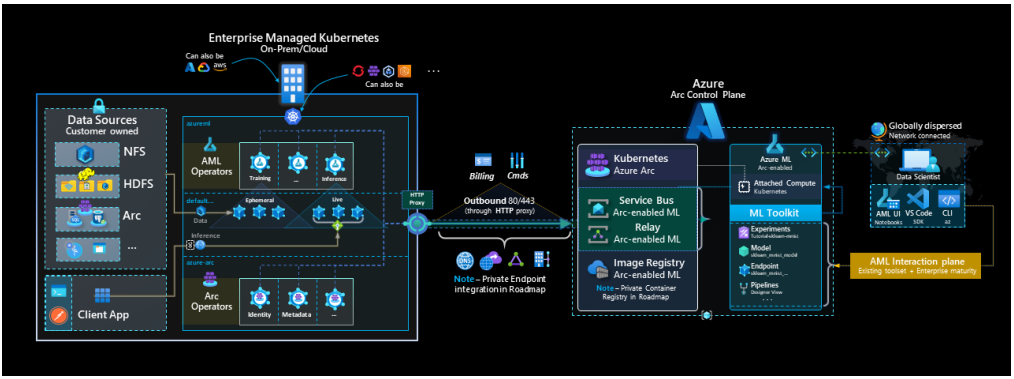
Azure Arc is a set of technologies that extends Azure management and services to any infrastructure. Its capabilities bring three main benefits to Azure Arc-enabled ML. Discover how machine learning can optimise your business through DSP machine learning services.
You might also be interested in...
Why Microsoft Azure is the future for building critical infrastructures
Managing and improving critical infrastructure, including utilities, transportation services, urban innovation and digital services is one of the most important functions of many organisations.
Microsoft Azure for hybrid and multi-cloud environments
This page seeks to demonstrate best practices, including warning signs and the essential actions that any business must take to enable hybrid environments.
Want to see what we can do for your business?
Get in touch with our specialists today and start your modernisation journey with industry experts.